I had some interesting conversation during a code review that I was asked to conduct for a simple query that a team had written to support their project monitoring. The team was specializing in quality assurance and had minimal development experience. The team had used variables of decimal data types in their script, but they were declared without any precision or scale. When I gave a review comment on the declaration of variables, I was asked the question:
Does it make a difference if we do not specify scale and precision when defining variables of decimal or numeric datatypes?
I often look forward to such encounters for two reasons:
- When I answer their questions, the process reinforces my concepts and learnings
- It helps me contribute to the overall community by writing a blog about my experience
When the question was asked, I honestly admitted that I did not have a specific answer other than it was the best practice to do so from a long-term maintainability standpoint. Post lunch, I did a small test which I showed the team and will be presenting today.
The Problem
In the script below, I take a decimal variable (declared without a fixed scale or precision) with value (20.16) and multiply it by a constant number (100) and then by another constant decimal (100.0). If one uses a calculator, the expected result is:
- 20.16 * 100 = 2016
- 20.16 * 100.0 = 2016
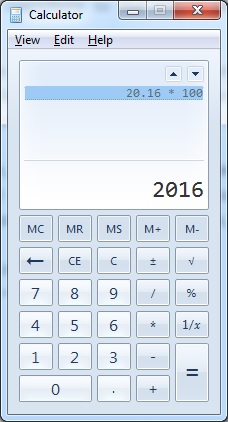
Expected results when we multiply a Decimal with another number using the calculator
However, when we perform the same test via SQL Server, we are in for a surprise:
DECLARE @dVal1 DECIMAL = 20.16;
SELECT (@dVal1 * 100) AS DecimalMultipliedByAnInteger,
(@dVal1 * 100.0) AS DecimalMultipliedByADecimal;
GO
As can be seen from the seen from the results below, we do not get the expected results, but we find that the decimal value was rounded off before the multiplication took place.
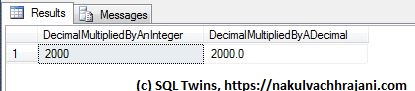
Although the test input value is declared as a decimal, the result appears to be based only on the significand, not the mantissa part of the input.
Root Cause
The reason behind this behaviour is hidden in the following lines of the SQL Server online documentation on MSDN (formerly known as “Books-On-Line”) for decimal and numeric data-types available here: https://msdn.microsoft.com/en-us/library/ms187746.aspx.
…s (scale)
The number of decimal digits that will be stored to the right of the decimal point….Scale can be specified only if precision is specified. The default scale is 0…
The real reason however is a few lines below – rounding.
Converting decimal and numeric Data
…By default, SQL Server uses rounding when converting a number to a decimal or numeric value with a lower precision and scale….
What SQL Server appears to be doing here is that when a variable of DECIMAL datatype is declared without a precision and scale value, the scale is taken to be zero (0). Hence, the test value of 20.16 is rounded to the nearest integer, 20.
To confirm that rounding is indeed taking place, I swapped the digits in the input value from 20.16 to 20.61 and re-ran the same test.
DECLARE @dVal1 DECIMAL = 20.61;
SELECT (@dVal1 * 100) AS DecimalMultipliedByAnInteger,
(@dVal1 * 100.0) AS DecimalMultipliedByADecimal;
GO
Now, the result was 2100 instead of 2000 because the input test value of 20.61 was rounded to 21 before the multiplication took place.
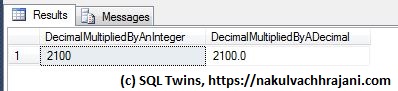
Because the test input value was declared as a decimal without precision and scale, rounding took place, resulting in a different result.
By this time, my audience was struck in awe as they realized the impact this behaviour would have had on their project monitoring numbers.
The Summary – A Best Practice
We can summarize the learning into a single sentence:
It is a best practice for ensuring data quality to always specify a precision and scale when working with variables of the numeric or decimal data types.
To confirm, here’s a version of the same test as we saw earlier. The only difference is that this time, we have explicitly specified the precision and scale on our input values.
DECLARE @dVal1 DECIMAL(19,4) = 20.16;
SELECT (@dVal1 * 100) AS DecimalMultipliedByAnInteger,
(@dVal1 * 100.0) AS DecimalMultipliedByADecimal;
GO
When we look at the results, we see that the output is exactly what we wanted to see, i.e. 2016.
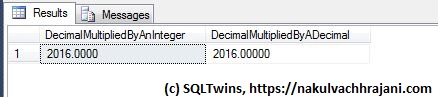
Because the test input value was declared as a decimal with precision and scale, no rounding took place and we got the expected result.
Further Reading
- decimal and numeric data types [MSDN Documentation]
Until we meet next time,
Be courteous. Drive responsibly.