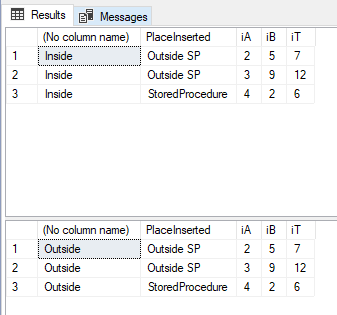
A few weeks ago, I wrote a piece on returning scalar values from a stored procedure using the OUTPUT clause. Shortly after, I got an interesting comment stating that the example outlined in the post was not working. There were no errors – it’s just that the output variables weren’t being set when the stored procedure was called.
Here’s the stored procedure which was shared in my earlier post.
USE [tempdb];
GO
IF OBJECT_ID('dbo.proc_AddNumbersWithMultipleOutputs','P') IS NOT NULL
BEGIN
DROP PROCEDURE [dbo].[proc_AddNumbersWithMultipleOutputs];
END
GO
CREATE PROCEDURE [dbo].[proc_AddNumbersWithMultipleOutputs]
@intA INT,
@intB INT,
@isSuccessfullyProcessed BIT OUTPUT, --Output variable #1
@resultC INT OUTPUT --Output variable #2
AS
BEGIN
SET NOCOUNT ON;
SET @isSuccessfullyProcessed = 0;
SET @resultC = 0;
BEGIN TRY
IF ((@intA IS NULL) OR (@intB IS NULL))
THROW 51000,'Input Parameters cannot be NULL',-1;
SET @resultC = @intA + @intB;
SET @isSuccessfullyProcessed = 1;
END TRY
BEGIN CATCH
SET @isSuccessfullyProcessed = 0;
SELECT ERROR_NUMBER(),
ERROR_MESSAGE(),
ERROR_SEVERITY(),
ERROR_STATE();
END CATCH
END
GO
And here’s the script that was not working as expected:
--In a separate window, run the following
DECLARE @inputA INT = 2; --Use NULL to throw exception
DECLARE @inputB INT = 3; --Use NULL to throw exception
DECLARE @outputC INT;
DECLARE @processingState INT;
EXEC [dbo].[proc_AddNumbersWithMultipleOutputs]
@intA = @inputA,
@intB = @inputB,
@isSuccessfullyProcessed = @processingState,
@resultC = @outputC;
SELECT @inputA AS 'Input A',
@inputB AS 'Input B',
@outputC AS 'Result',
@processingState AS 'IsTransactionSuccessfullyProcessed';
GO
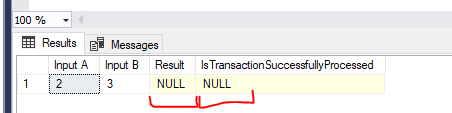
If you carefully review the script, you will realize that @processingState and @outputC do not have the OUTPUT parameter specification. Without this specification, SQL Server treats it as a normal input parameter. Hence, no value was being returned. No errors should be expected as well. This behavior is the default and backward compatible.
Further reading
- Specify Parameters in a Stored Procedure: https://learn.microsoft.com/en-us/sql/relational-databases/stored-procedures/specify-parameters?view=sql-server-ver17
Until we meet next time,
Be courteous. Drive responsibly.