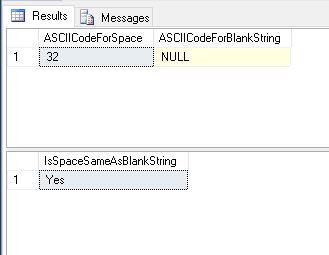
It was recently brought to my attention that a particular script was passing spaces when it should not. Here’s an example:
DECLARE @spaceCharacter NVARCHAR(1) = N' ';
DECLARE @blankCharacter NVARCHAR(1) = N'';
--Confirm that we are looking at different values
--The ASCII codes are different!
SELECT ASCII(@spaceCharacter) AS ASCIICodeForSpace,
ASCII(@blankCharacter) AS ASCIICodeForBlankString;
--Compare a blank string with spaces
IF (@spaceCharacter = @blankCharacter)
SELECT 'Yes' AS IsSpaceSameAsBlankString;
ELSE
SELECT 'No' AS IsSpaceSameAsBlankString;
GO
/* RESULTS
ASCIICodeForSpace ASCIICodeForBlankString
----------------- -----------------------
32 NULL
IsSpaceSameAsBlankString
------------------------
Yes
*/
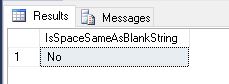
We then checked the LENGTH and DATALENGTH of both strings and noticed something interesting – the check on the LENGTH was trimming out trailing spaces whereas the check on the DATALENGTH was not.
DECLARE @spaceCharacter NVARCHAR(1) = N' ';
DECLARE @blankCharacter NVARCHAR(1) = N'';
--Check the length
SELECT LEN(@spaceCharacter) AS LengthOfSpace,
LEN(@blankCharacter) AS LengthOfBlankCharacter,
DATALENGTH(@spaceCharacter) AS DataLengthOfSpace,
DATALENGTH(@blankCharacter) AS DataLengthOfBlankCharacter;
GO
/* RESULTS
LengthOfSpace LengthOfBlankCharacter DataLengthOfSpace DataLengthOfBlankCharacter
------------- ---------------------- ----------------- --------------------------
0 0 2 0
*/

Often, we loose sight of the most basic concepts – they hide in our subconscious. This behaviour of SQL Server is enforced by the SQL Standard (specifically SQL ’92) based on which most RDBMS systems are made of.
The ideal solution for an accurate string comparison was therefore to also compare the data length in addition to a normal string comparison.
DECLARE @spaceCharacter NVARCHAR(1) = N' ';
DECLARE @blankCharacter NVARCHAR(1) = N'';
--The Solution
IF (@spaceCharacter = @blankCharacter)
AND (DATALENGTH(@spaceCharacter) = DATALENGTH(@blankCharacter))
SELECT 'Yes' AS IsSpaceSameAsBlankString;
ELSE
SELECT 'No' AS IsSpaceSameAsBlankString;
GO
/* RESULTS
IsSpaceSameAsBlankString
------------------------
No
*/
Further Reading
- How SQL Server Compares Strings with Trailing Spaces [KB316626]
Until we meet next time,
Be courteous. Drive responsibly.