On one of the forums, I encountered an interesting question the other day. The person asking the query had a table which had integers, null values and blank strings. In order to clean up this data, it was required to distinctly identify each of these combinations, but the simple queries below seemed to return the same results.
USE tempdb;
GO
SELECT sv.RowValue,
sv.RowValueInWords
FROM dbo.SomeValues AS sv
WHERE sv.RowValue >= 0;
GO
USE tempdb;
GO
SELECT sv.RowValue,
sv.RowValueInWords
FROM dbo.SomeValues AS sv
WHERE sv.RowValue >= '';
GO
Behind the scenes
This behaviour is not a bug, but is by design of SQL Server. What is happening is that when faced with conflicting data types, SQL Server tries to perform implicit conversions to arrive at a common data type which can be used to compare both the values.
Implicit conversion is done by following the rules of data type precedence, which dictates the sequence of implicit conversion, i.e. a data type with lower precedence is converted to a data type that has higher precedence. If such implicit conversion is not possible, and the user has not specified an explicit conversion, an error is returned.
Per the rules outlined by data type precedence, character data types (VARCHAR/NVARCHAR/TEXT/NTEXT) have a precedence that is lower than integers (INT). Hence, when faced with comparing characters and numbers, SQL Server will always implicitly convert the string to a number. A blank string (”) is therefore treated as a zero (0) when implicit conversion takes place.
Allow me to present this with a demo.
A demo
In the example below, I recreate the scenario referenced in the forum post – I have a table with numbers, zero and NULLs.
USE tempdb;
GO
SET NOCOUNT ON;
GO
--Safety Check
IF OBJECT_ID('dbo.SomeValues','U') IS NOT NULL
BEGIN
DROP TABLE dbo.SomeValues;
END
GO
--Creating the test table
CREATE TABLE dbo.SomeValues
(RowId INT NOT NULL IDENTITY(1,1),
RowValue INT NULL,
RowValueInWords VARCHAR(50) NOT NULL
);
GO
--Inserting values in the test table
INSERT INTO dbo.SomeValues(RowValue, RowValueInWords)
VALUES (0, 'Zero'),
(NULL, 'NULL'),
(1, 'One'),
(2, 'Two'),
(3, 'Three'),
(4, 'Four'),
(5, 'Five');
GO
Now let me run the query presented in the forum post.
USE tempdb;
GO
SELECT 'Query with Zero' AS QueryCondition,
sv.RowValue,
sv.RowValueInWords
FROM dbo.SomeValues AS sv
WHERE sv.RowValue >= 0;
GO
USE tempdb;
GO
SELECT 'Query with Blank' AS QueryCondition,
sv.RowValue,
sv.RowValueInWords
FROM dbo.SomeValues AS sv
WHERE sv.RowValue >= '';
GO
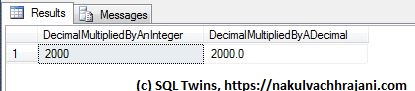
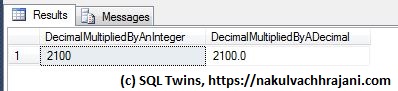
SQL Server returned me the same result because the blank string was implicitly converted to a zero (0).

Implicit Conversion may cause query filters to behave unexpectedly
Now, I will try and insert a blank string into the test table. We can see that the value will be inserted successfully.
--Let's try to insert a blank value
USE tempdb;
GO
INSERT INTO dbo.SomeValues (RowValue, RowValueInWords)
VALUES ('','Blank');
GO
/***********
RESULTS
***********/
--Command(s) completed successfully.
The question now is – what did SQL Server insert? If a blank value was indeed stored, it would violate the rules of the data type enforced by the column definition. Hence, I will now select the values from the table to see what was inserted.
USE tempdb;
GO
--See what was stored
SELECT sv.RowValue,
sv.RowValueInWords
FROM dbo.SomeValues AS sv;
GO

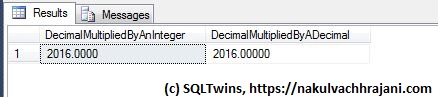
A blank string is inserted into the table as a zero due to implicit conversion
We can see from the results above that SQL Server performed an implicit conversion during the insert and stored a zero into the table. If the calling application tries to validate the data stored, it can continue to detect a mismatch between the expected and the actual data stored.
Summary
Implicit conversion is a boon if used wisely, but in most cases it can (and will) catch poorly written code and unsuspecting developers by surprise. Almost all operations in SQL Server are affected by implicit conversion as I have explored in the past with the following posts:
- Best Practices – Avoid Implicit conversions as they may cause unexpected issues (Part 01) [Blog Link]
- Best Practices – Avoid implicit conversions (Part 02) – Implicit conversions, COALESCE and ISNULL [Blog Link]
- Msg 206; Operand Type Clash; Return type of a CASE expression follows datatype precedence [Blog Link]
- Data Type Precedence in SQL Server [MSDN Link]
Until we meet next time,
Be courteous. Drive responsibly.