Recently, I was called upon to troubleshoot an interesting issue that came up with manipulating string termination characters (“\0”) using REPLACE. I wrote about the issue here.
As I was writing about the incident, I realized that if the data conditioning/manipulation script involves staging a “fixed” copy of the data one may end up with collation conflicts if the column collations were not specified as part of the column definition of these staging tables.
Allow me to demonstrate with an example.
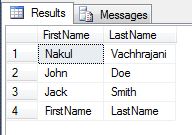
Basically what I will do in the script below is create a test table with some manufacturer and product data. I later attempt to combine the ManufacturerName and ProductName into a column called FullName. In order to do this, I stage the fixed/updated data into a staging table and later join that to the main table for the update.
--1. Safety check - drop before we recreate
IF OBJECT_ID('tempdb..#product','U') IS NOT NULL
DROP TABLE tempdb..#product;
GO
IF OBJECT_ID('tempdb..#tempProduct','U') IS NOT NULL
DROP TABLE tempdb..#tempProduct;
GO
--2. Create the table to be fixed
CREATE TABLE #product
(ManufacturerName VARCHAR(50) COLLATE Latin1_General_CI_AS,
ProductName VARCHAR(50) COLLATE Latin1_General_CI_AS,
FullName VARCHAR(100) COLLATE Latin1_General_CI_AS
);
GO
--3. Insert some test data
INSERT INTO #product (ManufacturerName,
ProductName,
FullName)
VALUES ('Microsoft-','SQL Server', NULL),
('Microsoft-','Windows', 'Microsoft Windows'),
('Google','Chrome', 'Google Chrome'),
('Microsoft-','Azure',NULL);
GO
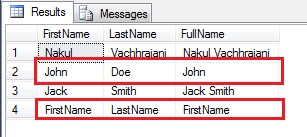
--4. Fix the data and store it to a staging table
SELECT ManufacturerName,
ProductName,
(REPLACE(p.ManufacturerName COLLATE Latin1_General_CI_AI, '-', ' ') + p.ProductName) AS FullName
INTO #tempProduct
FROM #product AS p;
GO
The key points to observe are:
- When doing the string manipulation, I explicitly specified a collation that is different from the collation of the original table (this may be required in case you are working on strings that need special handling)
- I did not explicitly specify the column definition for the staging table
What happens is that the collation of the output of a string function (REPLACE in this case) is same as that of the input string. This collation in the example is different from the collation of the main table. The temporary staging table is created with this different collation.
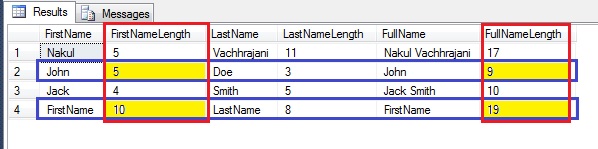
--5. Check out the meta-data of both the tables SELECT pisc.COLUMN_NAME, pisc.COLLATION_NAME AS SourceCollation, tpisc.COLLATION_NAME AS StagingCollation FROM tempdb.INFORMATION_SCHEMA.COLUMNS AS pisc INNER JOIN tempdb.INFORMATION_SCHEMA.COLUMNS AS tpisc ON pisc.COLUMN_NAME = tpisc.COLUMN_NAME WHERE pisc.TABLE_NAME LIKE '#product%' AND tpisc.TABLE_NAME LIKE '#tempProduct%' GO
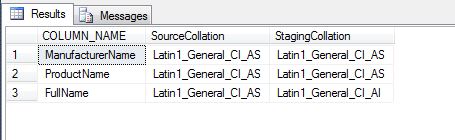
Now, let us see what happens when we try to execute the update:
--6. Try the update and see what happens UPDATE p SET p.FullName = tp.FullName FROM #product AS p INNER JOIN #tempProduct AS tp ON p.ManufacturerName = tp.ManufacturerName AND p.ProductName = tp.ProductName AND p.FullName <> tp.FullName; GO
Msg 468, Level 16, State 9, Line 44 Cannot resolve the collation conflict between "Latin1_General_CI_AI" and "Latin1_General_CI_AS" in the not equal to operation.
The update basically fails with a collation conflict error which could have easily been avoided by specifying the column definition (with appropriate collations) for the staging tables.
The problem demonstrated above can be reproduced with other string manipulation functions as well (e.g. SUBSTRING).
The moral of the story: Always follow best practices and specify a column definition when defining a table – permanent, staging or temporary.
Until we meet next time,
Be courteous. Drive responsibly.
Script for this post:
--1. Safety check - drop before we recreate
IF OBJECT_ID('tempdb..#product','U') IS NOT NULL
DROP TABLE tempdb..#product;
GO
IF OBJECT_ID('tempdb..#tempProduct','U') IS NOT NULL
DROP TABLE tempdb..#tempProduct;
GO
--2. Create the table to be fixed
CREATE TABLE #product (ManufacturerName VARCHAR(50) COLLATE Latin1_General_CI_AS,
ProductName VARCHAR(50) COLLATE Latin1_General_CI_AS,
FullName VARCHAR(100) COLLATE Latin1_General_CI_AS
);
GO
--3. Insert some test data
INSERT INTO #product (ManufacturerName, ProductName, FullName)
VALUES ('Microsoft-','SQL Server', NULL),
('Microsoft-','Windows', 'Microsoft Windows'),
('Google','Chrome', 'Google Chrome'),
('Microsoft-','Azure',NULL);
GO
--4. Fix the data and store it to a staging table
SELECT ManufacturerName, ProductName, (REPLACE(p.ManufacturerName COLLATE Latin1_General_CI_AI, '-', ' ') + p.ProductName) AS FullName
INTO #tempProduct
FROM #product AS p;
GO
--5. Check out the meta-data of both the tables
SELECT pisc.COLUMN_NAME, pisc.COLLATION_NAME AS SourceCollation, tpisc.COLLATION_NAME AS StagingCollation
FROM tempdb.INFORMATION_SCHEMA.COLUMNS AS pisc
INNER JOIN tempdb.INFORMATION_SCHEMA.COLUMNS AS tpisc ON pisc.COLUMN_NAME = tpisc.COLUMN_NAME
WHERE pisc.TABLE_NAME LIKE '#product%' AND tpisc.TABLE_NAME LIKE '#tempProduct%'
GO
--6. Try the update and see what happens
UPDATE p
SET p.FullName = tp.FullName
FROM #product AS p
INNER JOIN #tempProduct AS tp ON p.ManufacturerName = tp.ManufacturerName
AND p.ProductName = tp.ProductName
AND p.FullName <> tp.FullName;
GO
--7. Creating the test tables
IF OBJECT_ID('tempdb..#product','U') IS NOT NULL
DROP TABLE tempdb..#product;
GO
IF OBJECT_ID('tempdb..#tempProduct','U') IS NOT NULL
DROP TABLE tempdb..#tempProduct;
GO