
One of the reasons I enjoy working with Microsoft SQL Server because often I find that its behaviour is a classic case of GIGO (Garbage In Garbage Out). Jacob Sebastian (LinkedIn) always makes it a point to mention in his TechEd and Community Tech Days sessions that one must also treat SQL Server with respect, else it will create problems for us!
Based on my practical experience in resolving issues during code review and sometimes during bug-fixing, what I am going to discuss about today demonstrates that if we (i.e. SQL developers) do not respect SQL Server or feed it the wrong queries, the output will be wrong!
Composite Primary Keys
There are many cases when we have the primary key on a table as a composite key, i.e. comprised of one or more key columns. Let us assume that we are making an application for a courier company, and have divided the country into multiple zones. Each zone has a set of delivery centers supported by the company.
USE tempdb
GO
IF (OBJECT_ID('tempdb.dbo.IndexBehaviourTest') IS NOT NULL)
DROP TABLE tempdb.dbo.IndexBehaviourTest
CREATE TABLE IndexBehaviourTest (CityId INT NOT NULL,
ZoneId INT NOT NULL,
City VARCHAR(20),
PRIMARY KEY(CityId, ZoneId))
GO
INSERT INTO IndexBehaviourTest (CityId, ZoneId, City)
VALUES
(1, 1, 'Delhi'),
(2, 1, 'Chandigadh'),
(1, 2, 'Mumbai'),
(2, 2, 'Ahmedabad'),
(1, 3, 'Kolkotta'),
(2, 3, 'Guwhati'),
(1, 4, 'Bengaluru'),
(2, 4, 'Chennai')
GO
As you can see from the script above, both the ZoneId and the CityId together identify a unique delivery location. Such cases are ideal for use of a composite primary key.
All of us “know” that whenever we write a query, we need to use the full primary key as the qualifier/filter in the WHERE clause. However, those who have supported a product for long will know that often developers in a rush to get things out of the door throw caution to the wind and proceed with whatever works.
The errors that occur
An unexpected result set
Normally, when developers develop code and unit test, the focus is more on getting the code to work, not on the accuracy of the code. The developer would begin by inserting a few cities into the database, and then use a simple query to fetch the results.
USE tempdb
GO
--Insert some unit test data
INSERT INTO IndexBehaviourTest (CityId, ZoneId, City)
VALUES
(3, 1, 'Noida')
--Fetch the test data to unit test
SELECT * FROM IndexBehaviourTest WHERE CityId = 3;
GO
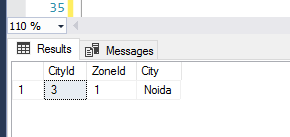
The developer would be happy that the code worked and that SQL Server performed an index seek as expected. The developer would therefore integrate the query into source control. However, an incomplete primary key has been used and outside of the unit test data, the user is bound to end up with an unexpected result set.
USE tempdb
GO
--Impact of using only part of the key
SELECT * FROM IndexBehaviourTest WHERE CityId = 2;
GO
As you can see, SQL Server returned us an incorrect result set because we requested “garbage” by not specifying the full primary key.
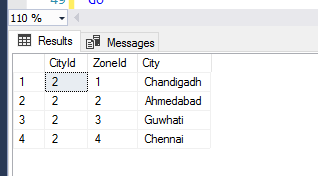
A performance hit
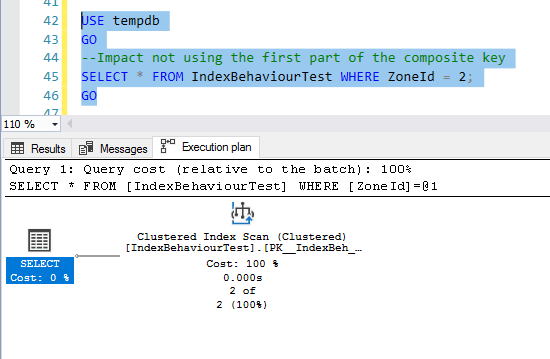
This is all about respecting SQL Server. If we do not use the first key column that makes up the composite key, we are not respecting SQL Server, and it will punish us by performing an index scan and thereby impacting performance:
USE tempdb
GO
--Impact not using the first part of the composite key
SELECT * FROM IndexBehaviourTest WHERE ZoneId = 2;
GO

Conclusion – Always use the full primary key
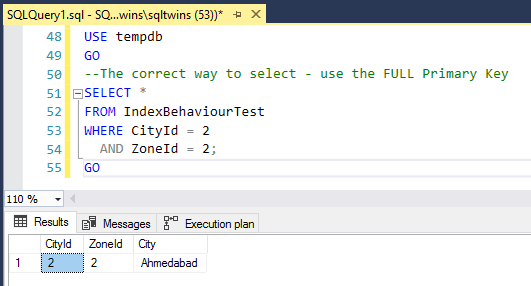
Always remember to treat SQL Server with respect, and never feed it junk to work upon. Always use the full primary key, and you will NEVER run into the specific issues mentioned above.
USE tempdb
GO
--The correct way to select - use the FULL Primary Key
SELECT *
FROM IndexBehaviourTest
WHERE CityId = 2
AND ZoneId = 2;
GO

Until we meet next time,
Be courteous. Drive responsibly.


Nice post. I remembered that in past, one of the developer used part of primary key and due to that at later stage, we faced lots of issues. Just by using proper primary key in WHERE condition, all the issues were resolved. Strange thing was code reviewer also missed that and good thing was it was not deployed in production..
I am always in favor of use FULL primary key.
LikeLike
The fact that you are seeing a Clustered Index Scan here has nothing to do with using only the first part of the composite primary key and everything to do with the number of rows in your example table. For a table of the size you created, given a predicate that will return more than one row, you will almost always see a scan.
Try the following example where we have a few thousand rows in table:
USE AdventureWorksDW –Or any other DBs with a good number of system and user table objects
GO
BEGIN TRY DROP TABLE #PKTest END TRY BEGIN CATCH END CATCH
CREATE TABLE #PKTest(SysID INT, TabId INT, SomeName NVARCHAR(128), PRIMARY KEY CLUSTERED(SysID, TabId))
INSERT #PKTest
SELECT TOP 10000 s.object_id, t.object_id, s.Name
FROM sys.objects s
CROSS JOIN sys.objects t
WHERE s.Type = N’S’ AND t.Type = N’U’
–You’ll get a seek here.
SELECT * FROM #PKTest WHERE SysID = (SELECT TOP 1 object_id FROM sys.objects WHERE type = ‘S’)
In this case we get a clustered index seek as expected. This would not be true, of course, if we used only the second (or third, or fourth…) part of our composite key as a predicate but this behavior is true for any idex.
Now whether or not the unit test in question is a valid one is a different issue. I would say it is not if the only unique constraint you’ve placed on the table
involved two columns and you only have one in your predicate! 🙂 But I think it’s important to make a distinction between that and always using all parts of a composite key to avoid index scans.
LikeLike
I wholeheartedly agree that, when a composite key is in use, that the entire key be used in all queries. The use of the PRIMARY KEY keywords in the CREATE TABLE statement should be the hint that the query developer uses to determine what uniquely identifies a row within the table.
There are two other pieces of documentation that should be available for a query developer to consult: a data dictionary and an ERD (Entity-Relationship Diagram) that would let the developer be able to discover primary keys (and foreign keys) related to the tables they are working with.
> However, those who have supported a
> product for long will know that often
> developers in a rush to get things out
> of the door throw caution to the wind
> and proceed with whatever works.
This is exactly why a short code review prior to deployment in production is so important. Those who skip this step will universally be bitten by it.
LikeLike
I respectfully disagree with your presumption here that you must use the full composite key in your queries. The composite key is a design consideration while the query is the means to get certain values. Using a composite key is a design consideration that (we assume) must have been necessary at design time to support the schema. It is not uncommon or unusual to use them and necessary in certain situations, such as querying against many-to-many relationships. That being said, it is up to the developer to understand the design and have a basic understanding of the query optimizer and how it deals with indexing in general and primary keys (clustered, unique, not null) in particular.
The developer should know that the query optimizer may not choose to use the same plan when the predicates in the WHERE clause include: Column1 or Column2 or both. IF IT IS NECESSARY to query for ZoneID=2, then your primary key will be of no value since it is the second column of the key. Your conclusion that you should “Always use the full primary key” in the query is not a matter of choice if you want all the cities in Zone 2. Queries are written to get a certain set of values – changing the predicates in the where clause is not the solution as it will not produce the results you want no matter what the performance. If the queries result in slow performance, then the design, indexing and table structure must be re-evaluated to support the query. In this simple case, if it is necessary to query on Zones, then you could add a non-clustered index.
Secondly, using composite keys will not return invalid results as you claim. In your own example, when you query for ‘CityID=2’, your results are perfectly accurate: 4 cities have a cityid=2 . Did I miss something?
LikeLike
Hello, Victor!
Thank-you for your comments.
Per the example, CityIds are unique within a zone. Hence, using only the City Id would fail to identify a unique delivery location (which is the business requirement).
I agree with you that developers should “know” about the design, but disagree that they are the only ones responsible if they don’t follow the design to the letter. It is often seen that even experienced developers fail to use the full primary key, sometimes in haste, or sometimes in over-assumption due to the nature of the data available in their database.
If we continue with the example in the post, consider a scenario wherein a logistics company is limited to a single zone only. It’s database would only have a single ZoneId and queries using only the CityId would continue to work fine. Many “accidental” T-SQL developers (or developers who primarily work on application code, but also write SQL queries “on the side”) would make the assumption that the database would never have a different ZoneId. Now, a couple of years down the line, the company decides to expand into other zones. At that time, all queries that use only the CityId would fail. This is the point that I was trying to drive home.
As correctly stated by Marc in the discussion, this is exactly why a code review is important. Sooner or later, skipping code review will make the team pay for the miss.
Therefore, the responsibility is not only on the developer, but also on the database development/administration team to ensure that applications are reviewed properly before deployment.
LikeLike