
Software Design, Assumptions and their side-effects
A few days ago, I tweeted a news piece that came to my attention on the name “NULL” causing computing systems to malfunction. When I shared it with my colleagues, a healthy discussion on how should software architectures handle NULL took place.
The key focus of discussion was of course that we need to be more globally aware and avoid generalization when defining business requirements (e.g. if one country does not commonly have people with surnames greater than 10 characters in length, doesn’t mean there aren’t people with longer surnames as highlighted here).
We also talked about detection of NULL values and manipulating them. In the world of databases, joins between tables are a common scenario and it is interesting to study the impact that NULL has on the JOIN operator in a T-SQL query.
NULL values and JOINs
I had encountered a scenario involving joining on NULL-able columns which I had encountered during a unit test I was executing. What happened was that rows were disappearing and initially I was unable to figure out why. Allow me to explain with a demo.
I have a simple table with software metrics like lines of code (LoC), story points, etc. for various modules. I also have a look-up table that gives me details of the measurement units, including provision to handle unknown sizing units (which was possible in our case for modules developed in fairly uncommon technologies).
When I joined between the metrics and the sizing units table, what happened was that metrics for the project in uncommon technologies did not appear!
DECLARE @someMetrics TABLE
(ModuleCode INT NOT NULL,
SizeValue INT NULL,
SizeUnit VARCHAR(10) NULL
);
DECLARE @unitMaster TABLE
(SizeUnit VARCHAR(10) NULL,
UnitDescription VARCHAR(50) NULL
);
INSERT INTO @unitMaster (SizeUnit,
UnitDescription
)
VALUES (NULL , 'Unit Unknown'),
('LOC', 'Lines of Code'),
( 'SP', 'Story Points');
INSERT INTO @someMetrics (ModuleCode,
SizeValue,
SizeUnit
)
VALUES (1, 1200, 'LOC'),
(3, 3, 'SP' ),
(6, 32, NULL ),
(7, 2500, 'LOC');
--Problem
SELECT sm.ModuleCode,
sm.SizeValue,
um.UnitDescription
FROM @someMetrics AS sm
INNER JOIN @unitMaster AS um ON sm.SizeUnit = um.SizeUnit;
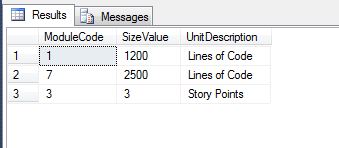
Metrics for NULL sizing units were filtered in the join process
The Root Cause
What is happening is that by default NULL compared with any value (NULL or otherwise) yields NULL. This is expected because when one of two values in a comparison is an unknown, there is no way to ascertain the result of the comparison and hence it has to be unknown, i.e. NULL.
In case of a join, the way SQL Server behaves is that all rows that match a given condition are fetched. Rows with conditions evaluating to “anything other than true” are filtered out. This is exactly what was happening in my case – since the columns used in the joined predicate had NULL values, the comparison yielded NULL (a non-true result) and hence these rows were filtered out.
The Fix
Option 01: The ideal fix is to ensure that the data never contains NULLs. Instead of NULL, a default value (anything suitable to the domain) can be used to indicate that the source system did not supply any value.
Option 02: In case changing the source data is not feasible, the query needs to be updated to substitute the NULL values for a chosen default as shown below.
DECLARE @someMetrics TABLE
(ModuleCode INT NOT NULL,
SizeValue INT NULL,
SizeUnit VARCHAR(10) NULL
);
DECLARE @unitMaster TABLE
(SizeUnit VARCHAR(10) NULL,
UnitDescription VARCHAR(50) NULL
);
INSERT INTO @unitMaster (SizeUnit,
UnitDescription
)
VALUES (NULL , 'Unit Unknown'),
('LOC', 'Lines of Code'),
( 'SP', 'Story Points');
INSERT INTO @someMetrics (ModuleCode,
SizeValue,
SizeUnit
)
VALUES (1, 1200, 'LOC'),
(3, 3, 'SP' ),
(6, 32, NULL ),
(7, 2500, 'LOC');
--One way to resolve the problem
SELECT sm.ModuleCode,
sm.SizeValue,
um.UnitDescription
FROM @someMetrics AS sm
INNER JOIN @unitMaster AS um
ON ISNULL(sm.SizeUnit,'NULL') = ISNULL(um.SizeUnit,'NULL');
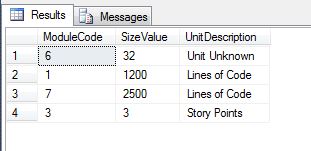
Using a chosen default instead of NULL in the join predicate
Conclusion
Irrespective of the business design, it is extremely important to have a strategy on handling of NULL values during system design. Most systems lack consistency in the way they allow for and handle NULL values.
Bringing in a set of standardized design practices on handling of NULL values makes it easier to predict system behaviour and also helps in re-engineering efforts whenever required to do so in the future.
Further Reading
- Why is it not a good idea to implement NOT NULL check as a CHECK constraint? [Blog Link here]
- SQL Server – CONCAT_NULL_YIELDS_NULL property [Blog Link here]
- Fun with temporary tables – Impact of ANSI_NULL_DFLT_ON [Blog Link here]
Until we meet next time,
Be courteous. Drive responsibly.

