
I have been working with SQL Server Integration Services (SSIS) recently. In many ways, SSIS is counter-intuitive if you have been working with the database engine for long (more than a decade in my case). Working with SSIS is more like working with any other .net framework based programming language (C# or VB.net). Over the next couple of days, I will be writing about some of the salient aspects of SSIS which should be kept in mind in case you are working on multiple SQL Server technologies.
Lookup Transformations – A key to successful system integrations
Cross-referencing of Enumerations
One of the key challenges for any system integration is to ensure that the enumerations and “default” values used in the source system (e.g. sales statuses, product categories, etc) align between the “source” & “target” systems.
Once the values aligned during business, high-level and low-level designs, implementation of this cross-referencing in SQL Server Integration Services (SSIS) is done by a data flow component called the “Lookup Transformation“. The Lookup transformation effectively performs a join between the input data with a reference data set. If values match, they are available in what is called the “Match Output” whereas values that do not match can be made available as a “No Match Output”. However, this comes with a tiny counter-intuitive behaviour that I learnt about the hard way.
The lookup performed by the lookup transformation is case-sensitive.
Demo
In order to demonstrate the case-sensitivity of lookup transformations, I have developed a SSIS package that does the following in a simple data-flow task:
- Get some static data from an OLEDB data source, basically some rows with text representation of numbers (One, Two, Three, and so on)
- The Lookup transform has a static mapping between the numeric and text values of various numbers – 1 through 10
- As the input data passes through the lookup transformation, we try to map the text values in the source data with the values available in the lookup transformation so that we can get the appropriate numeric representation
- In my demo, records that find a valid lookup are written to a recordset destination (it could be any valid destination), whereas records that do not match are written to another destination
- I have placed data viewers on the output pipelines to visually see the data being moved, which is what I will show below
The query used to generate the static data in the OLE DB source is provided below.
SELECT srcValues.RowName,
srcValues.RowValue
FROM (VALUES ('Row1','One'),
('Row2','Two'),
('Row3','three'),
('Row4','Four'),
('Row5','Five'),
('Row6','Six'),
('Row7','seven'),
('Row8','eight'),
('Row9','Nine'),
('Row10','Ten')
) AS srcValues (RowName, RowValue);
The query used to generate the lookup values for the lookup transform is provided below:
SELECT lookUpValues.Id,
lookUpValues.RowValue
FROM (VALUES (1, 'One'),
(2, 'Two'),
(3, 'Three'),
(4, 'Four'),
(5, 'Five'),
(6, 'Six'),
(7, 'Seven'),
(8, 'Eight'),
(9, 'Nine'),
(10, 'Ten')
) AS lookUpValues (Id, RowValue);
Observe that in the static source data, not all values have a consistent case – some are in sentence case, whereas some are in small case.
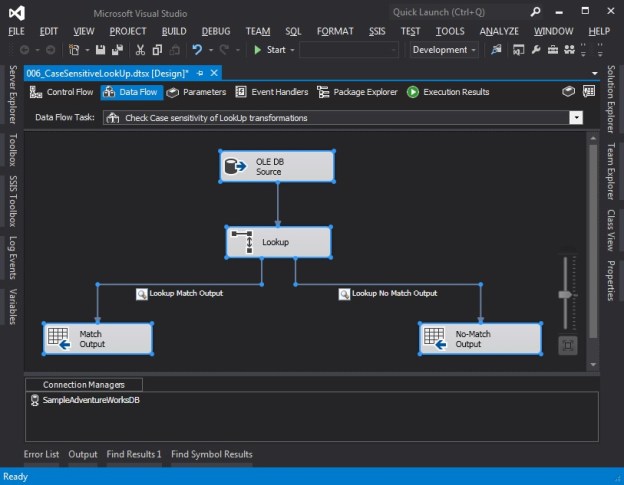
The screenshots below show the overall setup of the SSIS package.
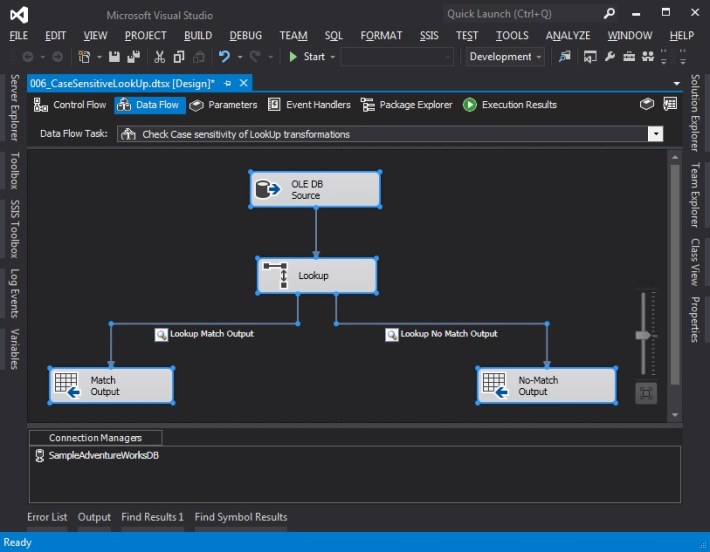
Data Flow Task used to demonstrate case-sensitivity of Lookup transformation
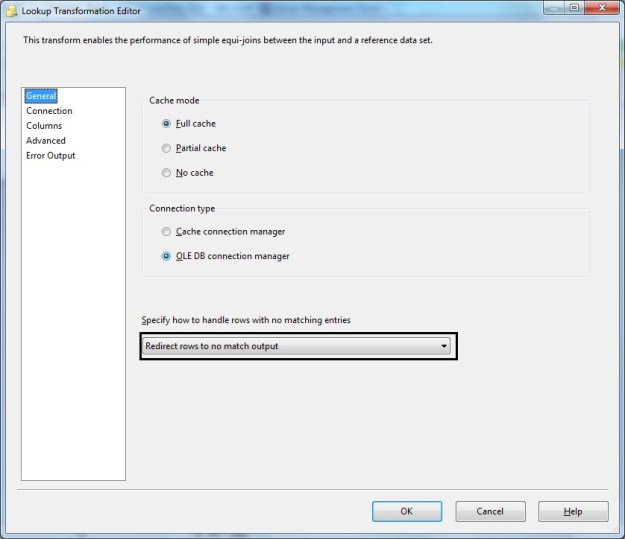
LookUp Transformation – General configuration (Notice redirection to no match output)
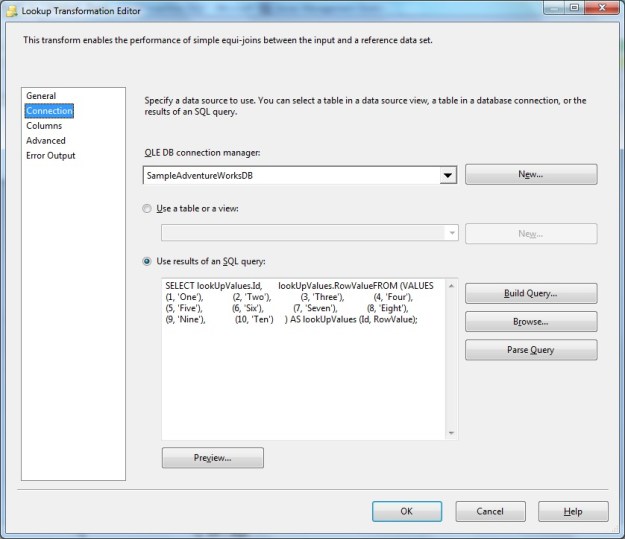
Lookup Transformation – Connection tab showing reference values
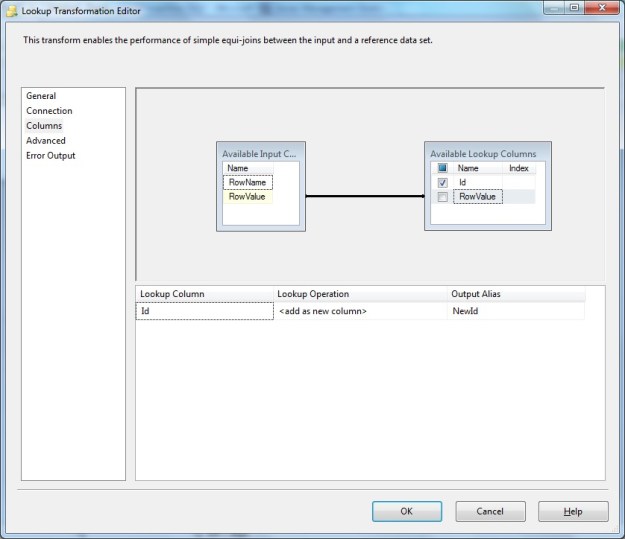
Lookup Transformation – Columns configuration
Notice here that we have used the text value from the source data (“RowValue” column) for matching/lookup to the reference data set. The reference Id is fetched to include in output.
If a match is found the “Match Output” should contain the matching row from the source combined with the Id from the reference/lookup data. This is seen in the data viewer output below.
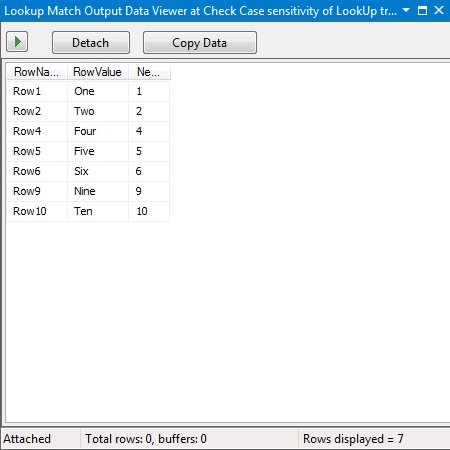
Lookup Transformation – Match Output (source rows with the Id from the reference data)
If a match is not found (which would be the case for the values with lower case in the source data), the “No Match Output” will contain the row from the source data that failed the lookup (since failures were redirected to the “No Match” output in the general configuration). Notice we do not get the Id from the reference because no match to the reference was found.
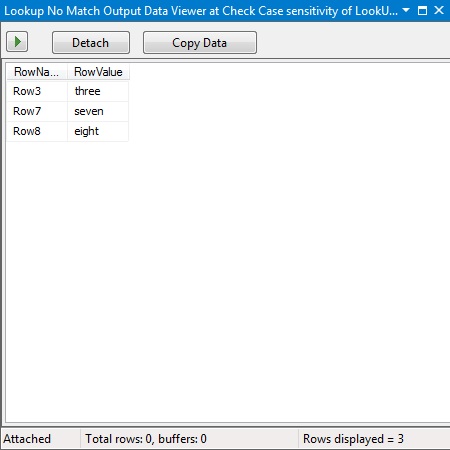
Lookup Transformation – No Match Output
Summary
When working with a case insensitive database, we often tend to take data quality with respect to case of the data for granted. Having data with inconsistent case has multiple repercussions (especially with data grouping in front end applications), but the biggest negative impact due to inconsistent case of text data is the inaccurate cross-referencing during a master data cleanup, system integration or data migration exercise.
Call to action
Do take a few cycles in your development to take a look at your data quality, and if necessary, implement required data cleansing to ensure that your lookup data, enumerations and master data are using a case that is correct and consistent with the domain and business requirements.
Until we meet next time,
Be courteous. Drive responsibly.

