It’s a well-known fact that using T-SQL cursors have a significant overhead on the query performance. At the same time, there are applications where one simply cannot use a set-based approach and use T-SQL cursors. Examples of such scenarios are when cascading complex calculations need to happen for each record (which are handled via CLR code or dedicated stored procedures) or when interfacing applications can only accept one record at a time.
Each T-SQL cursor has a specific scope. The cursor can be limited for use within the given stored procedure, trigger or batch making it a LOCAL cursor. If the context of the cursor is to be made available to multiple objects and scopes within the connection until explicitly deallocated, it is a GLOBAL cursor.
The cursor scope (GLOBAL/LOCAL) can be defined at the database level and can be overridden by the DECLARE CURSOR statement. Most implementations that I have seen rely on the database configuration. In such cases, if the cursor has been designed for GLOBAL access and someone changes the database configuration to a LOCAL cursor scope, the code will break.
Checking Default Cursor Scope: Database Configuration
Using T-SQL
A simple check on the [is_local_cursor_default] column of the [sys].[databases] will tell us if the default cursor scope is local or global.
--Confirm that Global cursors are set:
-- is_local_cursor_default = 0, i.e. GLOBAL cursor scope
-- is_local_cursor_default = 1, i.e. LOCAL cursor scope
--This is the default setting!
SELECT [sd].[is_local_cursor_default],
[sd].*
FROM [sys].[databases] AS sd
WHERE [sd].[database_id] = DB_ID('AdventureWorks2012');
GO
As the column name suggests, a value of 0 indicates that the cursor is GLOBAL, whereas a value of 1 indicates that the cursor is LOCAL.
Using SSMS
In SSMS, we can check the value of default cursor scope by looking at the “Options” page of the Database Properties window.
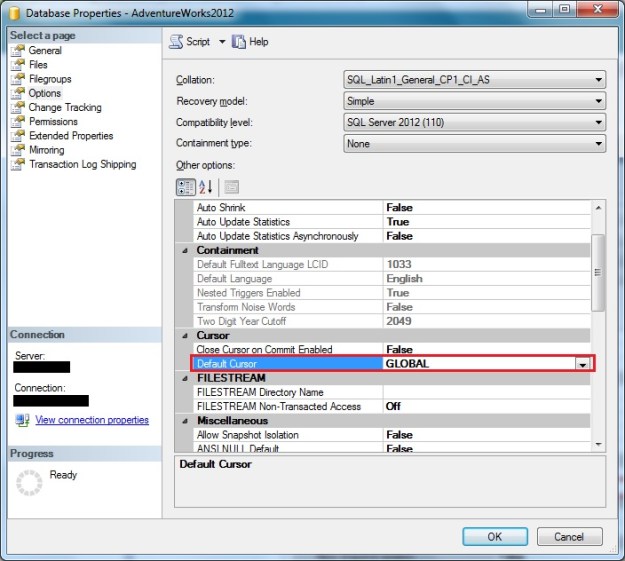
Checking “Default Cursor” scope set at the database level
Reproducing the Problem
For the purposes of this demo, I have created a simple stored procedure in the AdventureWorks database that is called once per each Product Category Id to get the product listing of products in that category.
USE AdventureWorks2012;
GO
--Create the test stored procedure
IF OBJECT_ID('Production.ProductListing','P') IS NOT NULL
DROP PROCEDURE Production.ProductListing;
GO
CREATE PROCEDURE Production.ProductListing
@productCategoryId INT
AS
BEGIN
SET NOCOUNT ON;
SELECT ppsc.ProductCategoryID AS ProductCateogry,
pp.ProductID,
pp.Name,
pp.ProductNumber,
pp.MakeFlag,
pp.FinishedGoodsFlag,
pp.StandardCost,
pp.ListPrice,
pp.SellEndDate,
pp.DiscontinuedDate
FROM Production.Product AS pp
INNER JOIN Production.ProductSubcategory AS ppsc
ON pp.ProductSubcategoryID = ppsc.ProductSubcategoryID
WHERE ppsc.ProductCategoryID = @productCategoryId;
END
GO
I can now create a cursor, access values from the cursor and call the stored procedure in an iterative manner. One would use this pattern when working with situations where dynamic SQL may need to be used to build the cursor (e.g. when fetching data from different tables of the same structure depending upon the configuration/situation).
USE AdventureWorks2012;
GO
--Create a CURSOR via Dynamic SQL and then
--use the values from the CURSOR to call the stored procedure
DECLARE @productListCategoryId INT;
EXEC sp_executesql @sql = N'DECLARE ProductListByCategory CURSOR
FAST_FORWARD READ_ONLY
FOR SELECT ppc.ProductCategoryID
FROM Production.ProductCategory AS ppc;
';
OPEN ProductListByCategory;
FETCH NEXT FROM ProductListByCategory INTO @productListCategoryId;
WHILE (@@FETCH_STATUS <> -1)
BEGIN
EXEC Production.ProductListing @productCategoryId = @productListCategoryId;
FETCH NEXT FROM ProductListByCategory INTO @productListCategoryId;
END
CLOSE ProductListByCategory;
DEALLOCATE ProductListByCategory;
GO
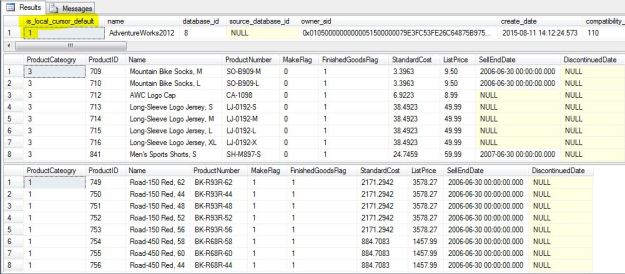
Normally the stored procedure calls will work just fine, as can be seen from the screenshot below.

Successful execution of cursor when Global cursor scope is configured
Now, let us change the cursor scope to LOCAL at the database level.
--Now, enable local cursors by default --for the AdventureWorks2012 database ALTER DATABASE [AdventureWorks2012] SET CURSOR_DEFAULT LOCAL; GO
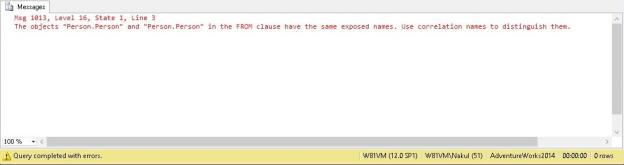
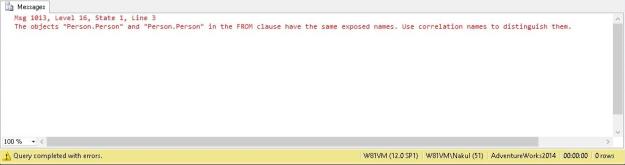
Running the same query as above now results in errors! The errors simply state that the cursor with the name “ProductListByCategory” does not exist.
USE AdventureWorks2012;
GO
--Create a CURSOR via Dynamic SQL and then
--use the values from the CURSOR to call the stored procedure
DECLARE @productListCategoryId INT;
EXEC sp_executesql @sql = N'DECLARE ProductListByCategory CURSOR
FAST_FORWARD READ_ONLY
FOR SELECT ppc.ProductCategoryID
FROM Production.ProductCategory AS ppc;
';
OPEN ProductListByCategory;
FETCH NEXT FROM ProductListByCategory INTO @productListCategoryId;
WHILE (@@FETCH_STATUS <> -1)
BEGIN
EXEC Production.ProductListing @productCategoryId = @productListCategoryId;
FETCH NEXT FROM ProductListByCategory INTO @productListCategoryId;
END
CLOSE ProductListByCategory;
DEALLOCATE ProductListByCategory;
GO
Msg 16916, Level 16, State 1, Line 75 A cursor with the name 'ProductListByCategory' does not exist.
Learning the hard way
The error message above is exactly what we received after we restored a copy of our development database on a loaned SQL Server instance to facilitate a ramp-up activity.
After conducting an impromptu code review to confirm that there were no other obvious issues (like deallocating the cursor without closing), we set out to compare the server and database settings with a working environment to rule out environmental issues. That’s when we saw that the DBA on the loaned server had changed the cursor scope setting of our database.
The Solution
The ideal solution to this issue has two parts – a configuration piece and a failsafe embedded into standard coding practice.
Set and document database level cursor scope requirements
One part of the ideal solution is to define and document the cursor scope requirements during database design. This should then be part of the documentation and checklists that are referenced when deploying the databases in production.
Database deployment and setup scripts should also have scripts to set the default scope, similar to the one below.
ALTER DATABASE [AdventureWorks2012] SET CURSOR_DEFAULT GLOBAL; GO
Ensure that cursor scope is defined when declaring a cursor
The fail-safe aspect of the solution is to ensure that when declaring a cursor, the code explicitly specifies whether the cursor is GLOBAL or LOCAL.
As can be seen from the example below, if scope is defined during cursor definition, it continues to work even if the cursor scope at the database level is not as expected.
--Set the cursor scope as GLOBAL when defining the cursor
--(as part of the DECLARE CURSOR statement)
--This overrides the default database configuration
USE AdventureWorks2012;
GO
DECLARE @productListCategoryId INT;
EXEC sp_executesql @sql = N'DECLARE ProductListByCategory CURSOR GLOBAL
FAST_FORWARD READ_ONLY
FOR SELECT ppc.ProductCategoryID
FROM Production.ProductCategory AS ppc;
';
OPEN ProductListByCategory;
FETCH NEXT FROM ProductListByCategory INTO @productListCategoryId;
WHILE (@@FETCH_STATUS <> -1)
BEGIN
EXEC Production.ProductListing @productCategoryId = @productListCategoryId;
FETCH NEXT FROM ProductListByCategory INTO @productListCategoryId;
END
CLOSE ProductListByCategory;
DEALLOCATE ProductListByCategory;
GO
If the Global scope is defined when declaring a cursor, the code works as expected irrespective of database configuration
Further Reading
The same error message (Msg. 16916) will be thrown due to a simple coding error – when we code deallocates a cursor before closing it first. This can easily be caught by implementing a code review practice and is a lesson for sustenance teams. That is what I recommend as a further reading into this topic.
Until we meet next time,
Be courteous. Drive responsibly.