Recently, I started writing about the nuances of SSIS which most accidental SSIS developers may frequently get stumped by due to the differences in behaviour over conventional T-SQL.
The OLE DB Destination
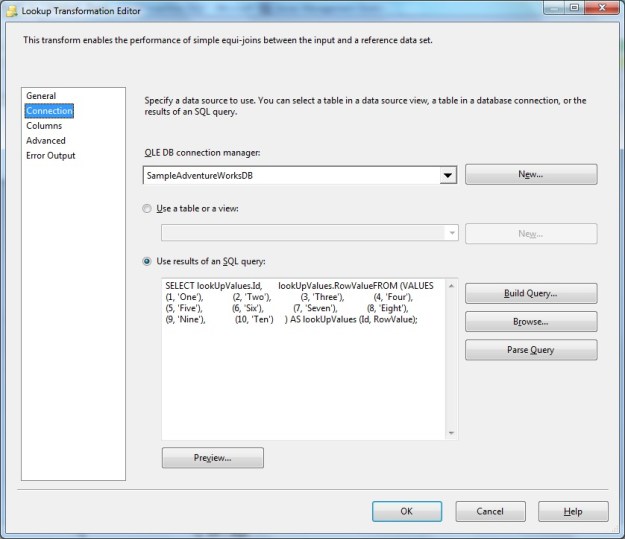
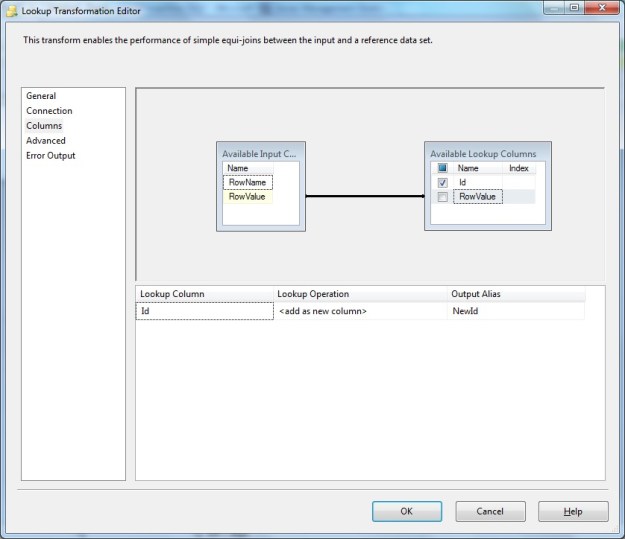
In my previous post, I started to explore the OLE DB destination. In order to load data as quickly into the destination as possible, the OLE DB destination allows us to use a “Fast Load” mode. The “Fast Load” option allows the data team to configure various options that affect the speed of the data load:
- Keep Identity
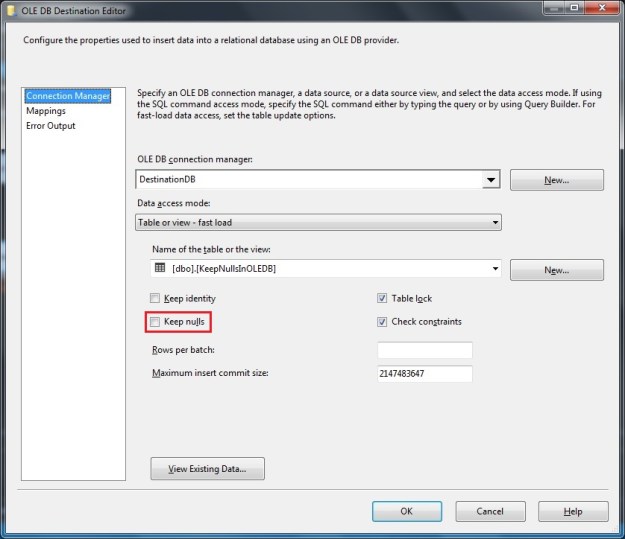
- Keep NULLs
- Table Lock
- Check Constraints
- Rows per Batch
- Maximum Insert Commit Size
I looked at the “Keep NULLs” option earlier, and today I will go over the “Keep Identity” option.
The “Keep Identity” option, as the name suggests controls the ability of the OLE DB destination task to insert data into an IDENTITY column. IDENTITY columns are quite a commonly used functionality to provide an auto increment value in a table. When migrating data from one system to another, it may be required to preserve the identity values during the migration.
Allow me to demonstrate the switch in action. In order to setup the demo, I created a table in the [tempdb] database on my SQL Server instance with an IDENTITY column, and inserted some test data into it.
USE tempdb;
GO
--Safety Check
IF OBJECT_ID('dbo.KeepIdentityInOLEDB','U') IS NOT NULL
BEGIN
DROP TABLE dbo.KeepIdentityInOLEDB;
END
GO
--Create table
CREATE TABLE dbo.KeepIdentityInOLEDB
([IdentityId] INT NOT NULL IDENTITY(1,1),
[ProductName] VARCHAR(255) NULL,
[ManufacturerName] VARCHAR(255) NULL
);
GO
--Initial sample test Data
INSERT INTO dbo.[KeepIdentityInOLEDB] ([ProductName], [ManufacturerName])
SELECT [ProductList].[ProductName],
[ProductList].[ManufacturerName]
FROM (VALUES ('Windows' , 'Microsoft'),
('SQL Server' , NULL ),
('VisualStudio','Microsoft'),
('MySQL' , 'Oracle' ),
('PeopleSoft' , 'Oracle' )
) AS [ProductList] ([ProductName], [ManufacturerName]);
GO
Default behaviour (Keep Identity unchecked)
When an OLE DB destination is configured to load a table with identity columns, the OLE DB destination fails validation if the identity column is mapped to the input.

Mapping identity column in the target table with a source value

Validation errors if identity columns are mapped and “Keep Identity” is unchecked (default)
Even if I forcibly try to run the package, the package fails.

Execution Failure when trying to execute the package with “Keep Identity” unchecked
Inserting data into Identity tables (Keep Identity checked)
If I check the “Keep Identity” checkbox, the validation error disappears and the package runs successfully.
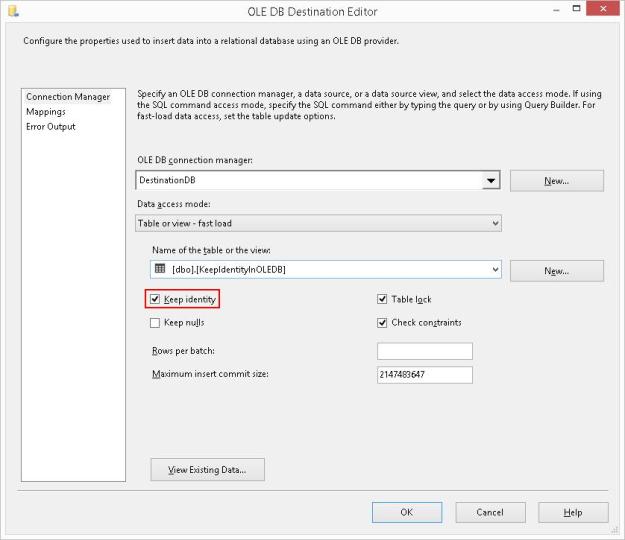
Checking the “Keep Identity” checkbox

Successful package execution with “Keep Identity” checked
When moving data from one system into another where the identity values can uniquely refer to the records being inserted, this option works perfectly.
However, keep in mind a side-effect of this checkbox. Let me take a look at the data that was inserted into the test table.

Inserting data with “Keep Identity” checked may cause duplicates in the identity column
The “Keep Identity” checkbox checked is like setting the IDENTITY_INSERT option to ON when inserting data into a table using T-SQL. Only difference is that the option is set to OFF once the package execution completes, and hence no explicit handling is required.
Further Reading
I have written a series of posts on T-SQL behaviour around identity values, and I trust you would find them interesting.
- An introduction to IDENTITY columns [Link]
- What are @@IDENTITY, SCOPE_IDENTITY, IDENT_CURRENT and $IDENTITY? [Link]
- Myths – IDENTITY columns cannot have holes or “gaps” [Link]
- Myths – Values cannot explicitly inserted into IDENTITY columns [Link]
- Myths – Duplicate Values cannot exist IDENTITY columns [Link]
- Myths – The value for SEED and INCREMENT must be 1 [Link]
- Myths – IDENTITY values (including SEED & INCREMENT) cannot be negative [Link]
- Myths – IDENTITY columns cannot be added to existing tables – Part 01 [Link]
- Myths – IDENTITY columns cannot be added to existing tables – Part 02 [Link]
- Myths – IDENTITY columns cannot have constraints defined on them [Link]
- Myths – IDENTITY columns do not propagate via SELECT…INTO statements [Link]
- Use IDENTITY() Function to change the Identity specification in a SELECT…INTO statement [Link]
Until we meet next time,
Be courteous. Drive responsibly.