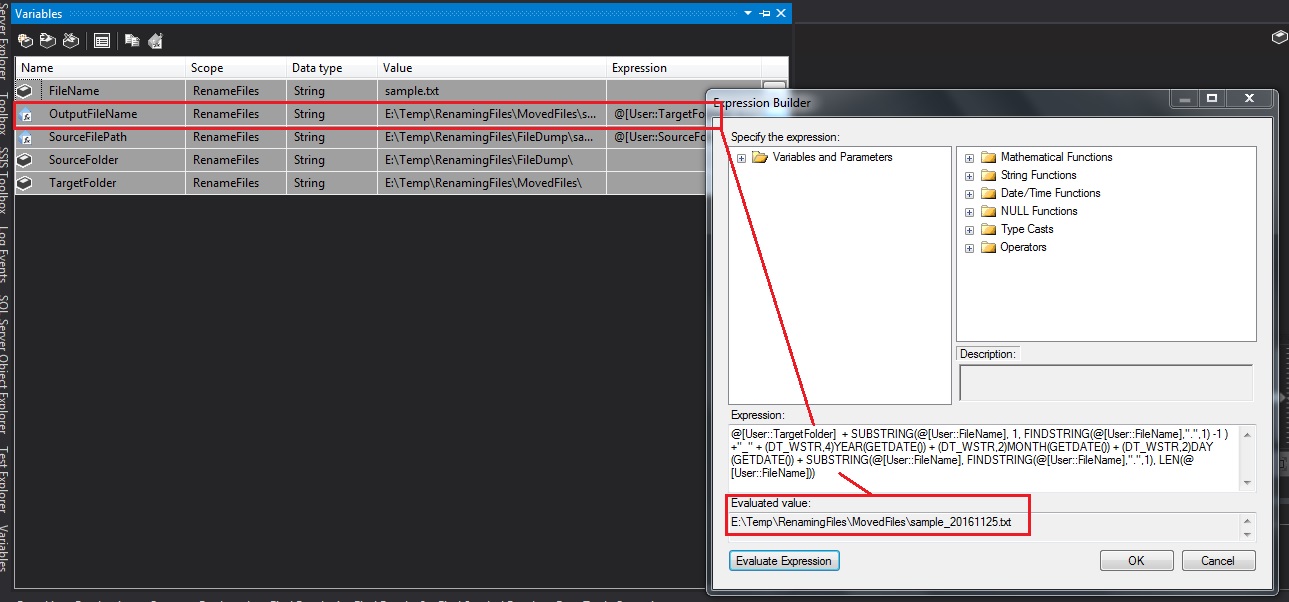
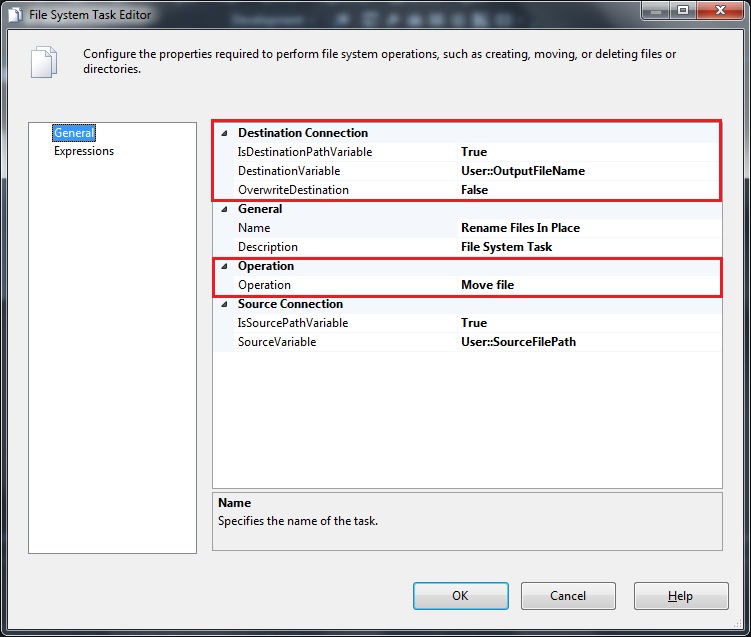
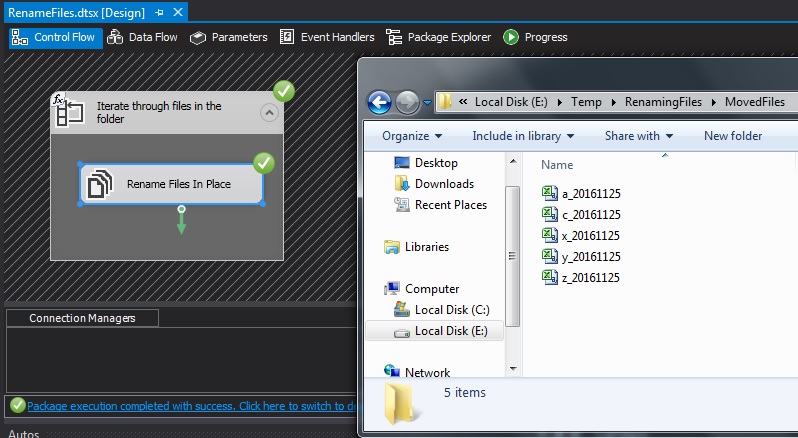
Today’s post is a quick one based on an experience I had recently. In one hour, I learnt two (2) new things that I didn’t know about Windows Notepad.
I was in an Azure training recently and working my way through a lab exercise. As I was building my environment, I had collected a bunch of tokens and connection strings in a Notepad file. And that’s when I ran into the first thing I didn’t know about Notepad.
The maximum length of text allowed in a line is 1024 characters
The following is a simulated text that I generated by replicating the English alphabet and the numbers (0-9) such that the resulting string is 1044 characters in length. In Notepad, the string automatically wraps at 1024 characters.
The workaround was simply to open the file in the Visual Studio IDE (which does not have the same limitations).

Text searches only work for first 128 characters
Immediately after I realized the word wrap limit, I was trying to search a connecting string (which was 133 characters in length) and landed up with multiple hits (which I was not supposed to).
After triple-checking everything, looked at what was being searched and that’s when I realized that the search box only takes 128 characters.

If you want to see it for yourself
You can use copies of the following string (37 characters in length) and an instance of Notepad:
abcdefghijklmnopqrstuvwzyz0123456789
Until we meet next time,
Be courteous. Drive Responsibly.