Developing SSIS packages is quite easy – it’s mostly drag and drop and some minor configuration, which is a really boon for someone who is new to SSIS. However, when it comes to tuning the package, one needs to understand the finer points of each task on the control flow. On each task, there are some options that help improving the performance of the data flow, whereas some others help regulate the quality of data being migrated.
The OLE DB Destination
I have written about the OLE DB destination. In order to load data as quickly into the destination as possible, the OLE DB destination allows us to use a “Fast Load” mode. The “Fast Load” option allows the data team to configure various options that affect the speed of the data load:
- Keep Identity
- Keep NULLs
- Table Lock
- Check Constraints
- Rows per Batch
- Maximum Insert Commit Size
Today, I will take a look at the “Check Constraints” option which controls the quality of the data “flowing” through the data flow task.
Leveraging Constraints in SQL Server
Before I go ahead and demonstrate the effect of the “Check Constraints” checkbox on the OLE DB Destination, I will reiterate the usage of constraints in Microsoft SQL Server table design. SQL Server supports multiple types of constraints, helping in maintaining data quality – both referential and domain:
- NOT NULL constraint – Prevents NULL values in a column
- UNIQUE constraint – Ensures values in a column are unique
- PRIMARY KEY – Uniquely identifies a row in a table
- FOREIGN KEY – They identify and enforce relationships between tables
- CHECK constraint – Checks the values being inserted against a defined set of business rules for valid data range values in the column
- DEFAULT constraint – Ensures that when an explicit value is not specified by the client, a default value is used so as not to break logical integrity of the data
Constraints that enforce referential and domain integrity are a physical implementation of the entity relationship and logical database design. As businesses grow and system architectures evolve, valid values for various enumerations also change and evolve. Values valid for a domain are enforced in the physical design via CHECK constraints.
Historical data may or may not confirm to the values enforced by current CHECK constraints today. For example, an expense workflow may have multiple stages which may not have existed in the past. While current data in the transaction systems would have been updated to confirm to the new enumerations, the historical data may still be as-is, i.e. valid in the past, but invalid today.
Check constraints and OLE DB Destination in SSIS
When moving such data over to a warehouse, the data transfer is a bulk data movement. By default, Microsoft SQL Server does not check constraints when loading data in bulk. SSIS allows you to control this behaviour when using the OLE DB transformation.
Demo
For this demo, I have a fairly simple scenario – a user registration table that enforces the following simple rules:
- A basic check for the validity of E-mail address
- The user registering must be 18 years in age or older
These checks are enforced by using CHECK constraints, and the DDL is provided below for your kind reference.
USE tempdb;
GO
--Safety Check
IF OBJECT_ID('dbo.UserRegistration','U') IS NOT NULL
BEGIN
DROP TABLE dbo.UserRegistration;
END
GO
CREATE TABLE dbo.UserRegistration
(UserId INT NOT NULL IDENTITY(1,1),
UserName VARCHAR(20) NOT NULL,
UserPassword VARCHAR(20) NOT NULL,
UserEmail VARCHAR(50) NULL,
UserBirthDate DATE NOT NULL
);
GO
--Primary Key
ALTER TABLE dbo.UserRegistration
ADD CONSTRAINT pk_UserRegistrationUserId PRIMARY KEY CLUSTERED (UserId);
GO
--User must have a valid E-mail
--(basic checking done here)
ALTER TABLE dbo.UserRegistration
ADD CONSTRAINT chk_UserRegistrationUserEmail
CHECK (UserEmail LIKE '[a-z,0-9,_,-]%@[a-z,0-9,_,-]%.[a-z][a-z]%');
GO
--User must be at least 18 years in age
ALTER TABLE dbo.UserRegistration
ADD CONSTRAINT chk_UserRegistrationBirthDate
CHECK (DATEDIFF(YEAR,UserBirthDate,GETDATE()) >= 18);
GO
In my SSIS package, I have used a standard data flow task. The OLE DB source uses a query that creates some valid and invalid data which I would like to insert into the destination [dbo].[UserRegistration] table. Below is the T-SQL query used for the source and screenshots of my data flow task.
SELECT TestData.UserName,
TestData.UserPassword,
TestData.UserEmail,
TestData.UserBirthDate
FROM
(VALUES --Valid Data
('SQLTwins1','SQLTwins@Pwd1','validEmail1@somedomain.com','1960-01-01'),
('SQLTwins2','SQLTwins@Pwd2','validEmail2@somedomain.com','1970-01-01'),
--Invalid Email
('SQLTwins3','SQLTwins@Pwd3','invalidEmail@somedomain' ,'1970-01-01'),
--Invalid BirthDate
('SQLTwins4','SQLTwins@Pwd4','validEmail4@somedomain' ,'2016-01-01'),
--Invalid Email & BirthDate
('SQLTwins5','SQLTwins@Pwd5','invalidEmail' ,'2016-01-01')
) AS TestData (UserName, UserPassword, UserEmail, UserBirthDate);

OLE DB Source for checking bypass of the check constraints during bulk inserts

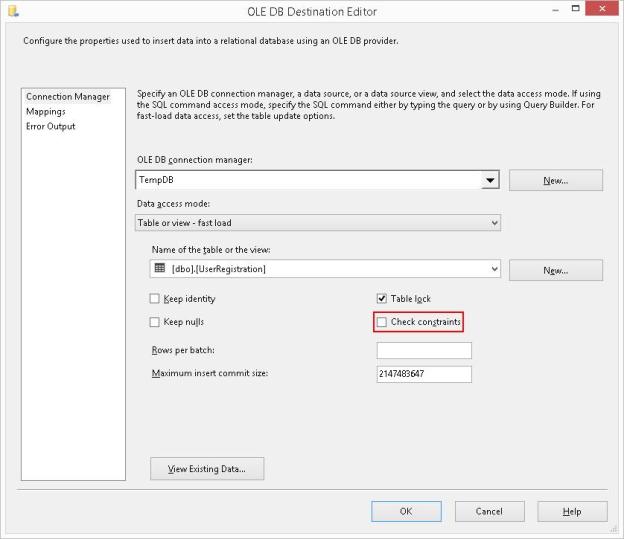
OLE DB Destination with Fast Load options, notice the “Check constraints” is checked by default
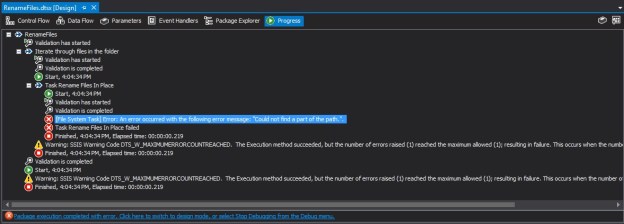
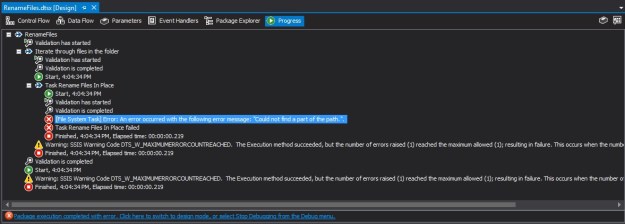
Notice that by default, the CHECK Constraints checkbox is checked. When I run the package by keeping CHECK constraints enabled, the package fails during execution.

SSIS Package failure when one or more input values violate CHECK constraints
Looking at the package progress log, I can confirm that the package failed because the data violated check constraints when inserting into the table. The error has been formatted below to enhance readability.
[Insert into UserRegistration table [2]] Error: SSIS Error Code DTS_E_OLEDBERROR.
An OLE DB error has occurred. Error code: 0x80004005.
An OLE DB record is available. Source: "Microsoft SQL Server Native Client 11.0"
Hresult: 0x80004005 Description: "The statement has been terminated.".
An OLE DB record is available. Source: "Microsoft SQL Server Native Client 11.0"
Hresult: 0x80004005
Description: "The INSERT statement conflicted with the CHECK constraint "chk_UserRegistrationUserEmail".
The conflict occurred in database "tempdb", table "dbo.UserRegistration", column 'UserEmail'.".
I now edit the package to uncheck the “Check Constraints” checkbox on the OLE DB Destination.

Unchecking the “Check constraints” checkbox on the OLE DB Destination
Running the package again results in success.
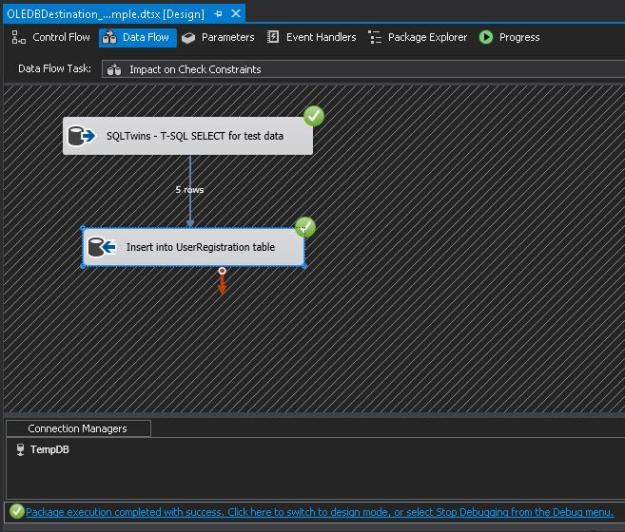
Successful Package Execution with “Check constraints” unchecked, i.e. data violating check constraints was successfully inserted
I now validate the data in the [dbo].[UserRegistration] table. I can see that data violating check constraints was successfully inserted.
USE [tempdb];
GO
SELECT [ur].[UserId],
[ur].[UserName],
[ur].[UserPassword],
[ur].[UserEmail],
[ur].[UserBirthDate]
FROM [dbo].[UserRegistration] AS [ur];
GO

Confirmation that constraints were not checked during insertion of data by the SSIS package
Important Notes
- Unchecking “Check Constraints” only turns off the checks for check constraints
- Referential and other integrity constraints (NOT NULL, Foreign Key, Unique Key, etc) continue to be enforced
Conclusion
The OLE DB destination task is a very powerful way to load data into SQL Server table in a short duration of time. At the same time, it can also cause bad data to be inserted into the destination if not used wisely.
Turn the Check Constraints option off to optimize the data load when you are sure that:
- Source data has expected discrepancies which are acceptable to the business/domain OR source data is correct
- Re-validation of the check constraints will be done as a post migration process to make all constraints trusted (disabling check constraints would have marked them as non-trusted)
Further Reading:
Until we meet next time,
Be courteous. Drive responsibly.